On-Prem & Cloud — My Infrastructure
A full breakdown of my infrastructure in 2026 — Proxmox cluster, Talos Kubernetes, GitOps with Flux, Oracle Cloud VPS, Tailscale mesh, and a full DR plan.

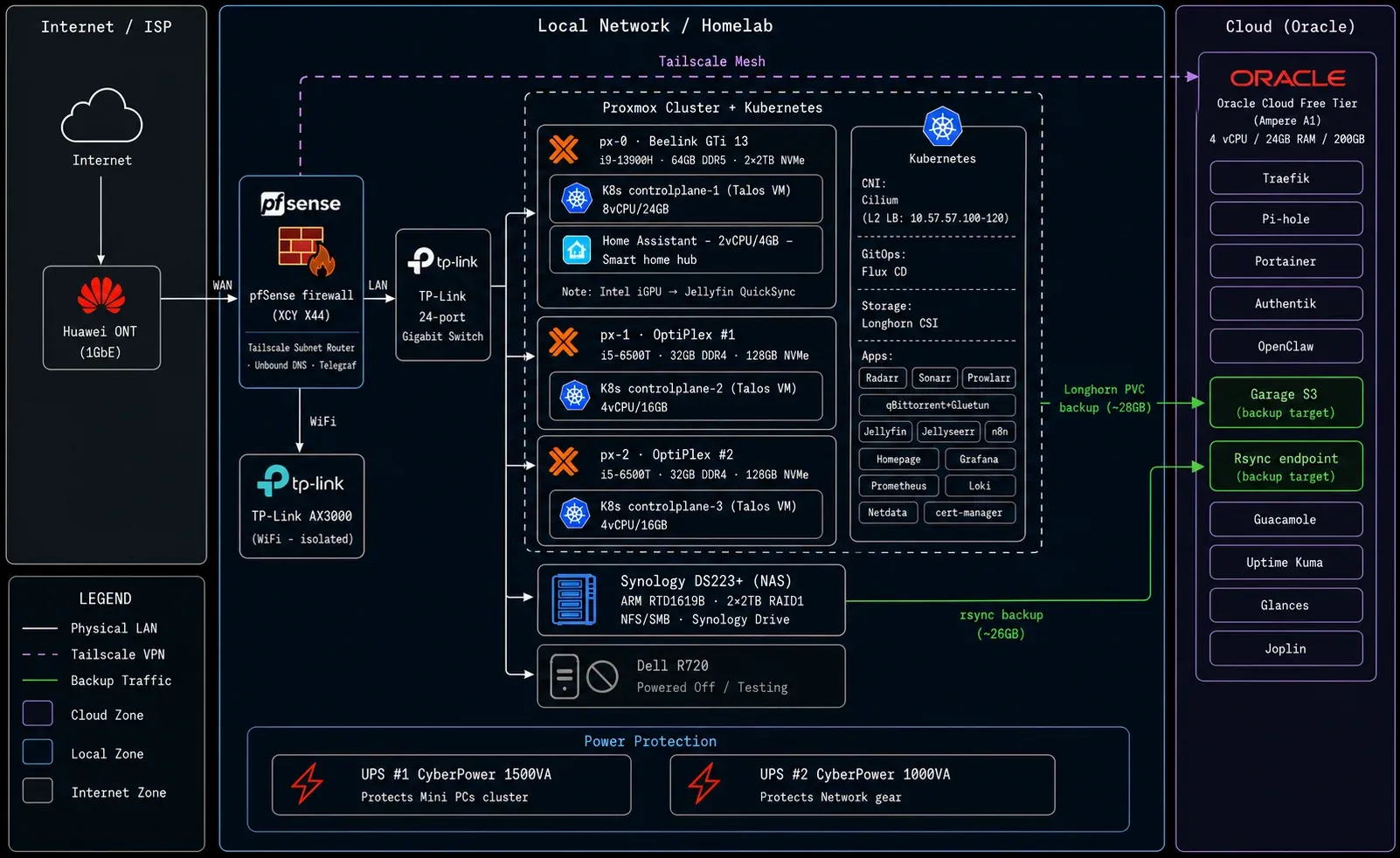
The short version: three mini PCs running a Proxmox cluster, a 3-node Talos Kubernetes cluster on top, a Synology NAS for storage, and an Oracle Cloud VPS as the off-site anchor — all on one Tailscale mesh, all managed from a single Git repo. The rest of this post is the long version.
The big shift from previous iterations was moving away from the Dell R720. A 2U rack server with dual Xeons and 192GB ECC RAM sounds good on paper, but 120–150W at idle and a jet-engine fan profile gets old fast when it’s running 24/7 in your home. I replaced it with a Beelink GTi 13 as the main node — more performance per watt, completely silent, and a fraction of the electricity bill. Two OptiPlex Micro 3050s round out the Proxmox cluster. Same three-node HA, drastically less noise and power.
This post is a living reference — I update it when something significant changes.
Hardware
Compute
| Device | CPU | RAM | Storage | Purpose |
|---|---|---|---|---|
| Beelink GTi 13 | i9-13900H (14C/20T) | 64GB DDR5 | 2× 2TB NVMe | Proxmox (px-0) |
| OptiPlex #1 | i5-6500T (4C/4T) | 32GB DDR4 | 128GB NVMe | Proxmox (px-1) |
| OptiPlex #2 | i5-6500T (4C/4T) | 32GB DDR4 | 128GB NVMe | Proxmox (px-2) |
| Synology DS223+ | ARM RTD1619B | 2GB | 2× 2TB RAID1 | NAS/Media |
Network Gear
| Device | Model | Specs | Purpose |
|---|---|---|---|
| ONT | Huawei | 1GbE | ISP Gateway |
| Firewall | XCY X44 | 8× 1GbE | pfSense Router |
| WiFi | TP-Link AX3000 | WiFi 6 | Wireless AP |
| Switch | TP-Link | 24-port | Core Switch |
Network
Three dedicated physical interfaces on pfSense:
WAN Interface → Orange ISP (Bridge Mode)LAN Interface → Homelab NetworkWiFi Interface → Guest/IoT IsolationWarning
WiFi clients are firewalled from homelab services, except whitelisted ones like Jellyfin.
pfSense
A fanless mini PC from AliExpress (~200€) running pfSense for 3+ years: XCY X44 on AliExpress
Tailscale Subnet Router exposes the entire homelab to the cloud VPS without installing Tailscale on every device. Also the solution to CGNAT — when your ISP doesn’t give you a public IP, this gets you in. Full setup guide →
Unbound DNS runs as a local recursive resolver with domain overrides for *.k8s.merox.dev pointing to K8s-Gateway.
Telegraf pushes system metrics to Grafana.
Firewall rules: WiFi → LAN blocks everything except whitelisted apps; LAN → WAN allows all; WAN → Internal blocks all except explicitly exposed services.
Tailscale Mesh
Tailscale creates a flat network across all locations — the homelab rack and the Oracle Cloud VPS both appear on the same mesh. No VPN tunnels to configure, no firewall holes to punch.
The Subnet Router on pfSense means every device in the homelab (including things like the Synology and iDRAC interfaces) is reachable from anywhere on the mesh without touching their individual configs.
Virtualization
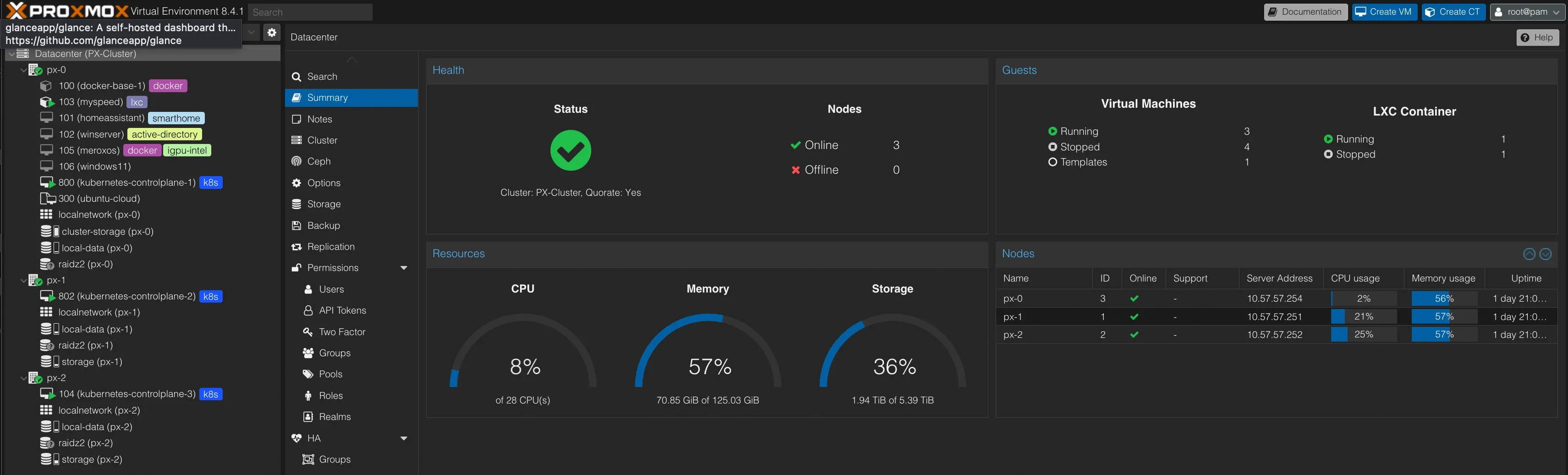
Proxmox Cluster
Three-node cluster across the mini PCs — px-0 is the Beelink (the workhorse), px-1 and px-2 the OptiPlexes (specs in the hardware table above). Each node runs one Talos VM, so Kubernetes has HA across physical hosts with no single point of failure.
Storage:
| Pool | Type | Used | Total |
|---|---|---|---|
| cluster-storage | ZFS | 713GB | 899GB |
| synology-nas | NFS | 985GB | 1.4TB |
| local-data | dir | 177GB | 812GB |
Current VMs:
| VM | Purpose | Specs | Status |
|---|---|---|---|
| kubernetes-controlplane-1 | K8s node (px-0) | 8vCPU/24GB | Running |
| kubernetes-controlplane-2 | K8s node (px-1) | 4vCPU/16GB | Running |
| kubernetes-controlplane-3 | K8s node (px-2) | 4vCPU/16GB | Running |
| Home Assistant | Smart home hub | 2vCPU/4GB | Running |
| Windows 10 | Lab / testing | 4vCPU/12GB | Stopped |
| Windows Server 2019 | AD Lab | 8vCPU/14GB | Stopped |
| Windows 11 | Remote desktop | 8vCPU/16GB | Stopped |
Intel Iris Xe GPU on px-0 is passed through to the kubernetes-controlplane-1 VM for Jellyfin hardware transcoding (Intel QuickSync). GPU passthrough guide →
Synology DS223+
Dual purpose: NFS/SMB shares for the ARR stack (still experimenting with both protocols), and personal cloud via Synology Drive.
After 3 years of self-hosting Nextcloud, I switched. Better performance, native mobile apps that actually work, and zero maintenance. Sometimes the best self-hosted solution is the one you never have to think about.
Power Management
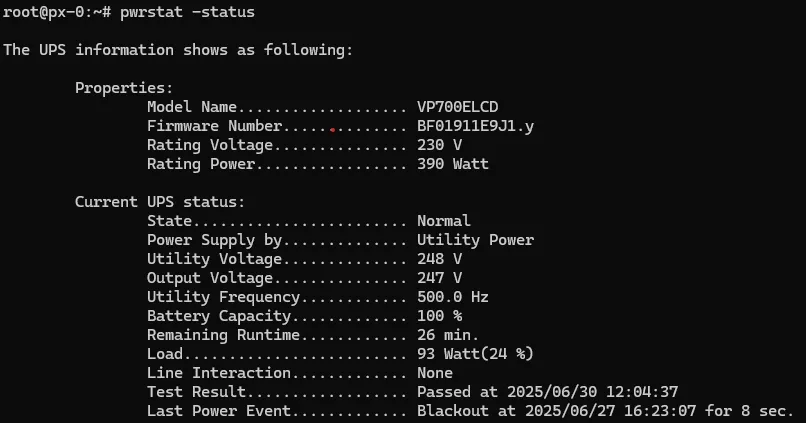
Two CyberPower UPS units — 1500VA for the Proxmox mini PCs, 1000VA for the network gear. When power fails, a cascading shutdown kicks in — Kubernetes nodes drain properly before Proxmox hosts go down.
| Feature | Implementation | Purpose |
|---|---|---|
| pwrstat | USB to GTi13 Pro | Automated shutdown orchestration |
| SSH Scripts | Custom automation | Graceful cluster shutdown |
| Monitoring | Telegram alerts | Real-time power notifications |

Note
The Dell R720 is in the rack but currently off — it’s running NixOS for learning and exploration, not part of the active production stack. iDRAC7 Enterprise gives remote console access when needed. R720 setup post →
Kubernetes
Fair warning: this is where I went full “because I can” mode. If you just want to run services, Docker is the right answer. But if you want to learn enterprise-grade container orchestration in your homelab, keep reading.
The starting point: onedr0p/cluster-template
Talos OS was the first immutable, declarative OS I’d run. After a few days of troubleshooting, I was sold.
Tip
Why Talos over K3s? Immutable OS means less maintenance, GitOps-first design, declarative everything, and it’s closer to what you’d run in production.
My infrastructure repo: github.com/meroxdotdev/infrastructure
Key customizations:
| Component | Modification | Reason |
|---|---|---|
| Storage | Longhorn CSI | Simpler PV/PVC management |
| Talos Patches | Custom machine config | Longhorn requirements |
| Custom Image | factory.talos.dev | Intel iGPU + iSCSI support |
GitOps structure:
kubernetes/apps/├── cert-manager/ # TLS automation├── default/ # Production workloads├── flux-system/ # Flux operator + instance├── kube-system/ # Cilium, CoreDNS, NFS CSI, metrics-server├── network/ # k8s-gateway, Cloudflare tunnel + DNS├── observability/ # Prometheus, Grafana, Loki└── storage/ # Longhorn configuration
Deployed apps:
| App | Purpose | Notes |
|---|---|---|
| Radarr | Movie automation | NFS to Synology |
| Sonarr | TV automation | NFS to Synology |
| Prowlarr | Indexer manager | Central search |
| qBittorrent | Torrent client | Gluetun sidecar + SurfShark WireGuard VPN |
| Jellyseerr | Request management | Public via Cloudflare |
| Jellyfin | Media server | Intel QuickSync enabled |
| Homepage | Dashboard | |
| Grafana | Metrics dashboards | |
| Prometheus + Alertmanager | Metrics collection + alerts | |
| Loki + Promtail | Log aggregation | |
| Netdata | Per-node system monitoring | DaemonSet — one agent per K8s node |
| cert-manager | TLS certificate automation | ACME via Let’s Encrypt |
The live dashboard is public — current service status at inside.merox.dev.
LoadBalancer IPs are handled by Cilium’s L2 announcement — a pool of addresses (10.57.57.100–120) announced directly on the LAN via ARP, no external load balancer needed. Services like qBittorrent, k8s-gateway, and the Cloudflare tunnel endpoint each get a dedicated IP from this pool.
Cluster Rebuild & Disaster Recovery
With declarative config for everything and Flux keeping state in Git, a full cluster rebuild takes ~35 minutes — provision the Talos VMs, bootstrap, and a single command restores all Longhorn volumes from S3 and reconciles every app:
# Phase 2 K8s restore — one command does everythingtask bootstrap:appstask longhorn:restoretask longhorn:restore handles the full sequence automatically — backup target, volume restore from Garage S3, PersistentVolumes with correct claimRefs, Flux reconcile. Persistent data survives even if all three Proxmox nodes die simultaneously, because the backups live off-site on the VPS. Observability (Prometheus, Loki, Grafana) starts fresh — metrics and log history is deliberately not backed up, and Grafana dashboards are provisioned from Git anyway.
The repo ships the whole DR toolkit around this: pre-flight checks, per-phase verification scripts, and Terraform to spin DR VMs up and down on Proxmox (task dr:create-vms). The step-by-step runbook is DR.md (tested end-to-end 2026-06-06); full rebuild from scratch — VPS, cluster, agents — is DEPLOY.md. Restore walkthrough with screenshots: Restoring from Longhorn Backups →
Warning
Back up two things before decommissioning any node: age.key (losing it = losing all SOPS-encrypted secrets) and ~/.openclaw/.env (Anthropic API key + Telegram tokens).
Cloud
The Oracle Cloud Free Tier Ampere A1 instance (4 vCPU / 24GB RAM / 200GB disk) is the off-site anchor of the entire setup. It’s not just a place to park Docker containers — it’s the external access layer, the backup target, and the recovery fallback.
Everything on it is managed through a single Portainer instance at cloud.merox.dev:
Services
| Service | Purpose |
|---|---|
| Traefik | SSL termination for all VPS services |
| Cloudflare Tunnel | Outbound-only tunnel for inside.merox.dev, sso.merox.dev, rmt.merox.dev, status.merox.dev, files.merox.dev — zero inbound ports |
| Pi-hole | Dedicated Tailscale split-DNS |
| Portainer | Container management |
| Authentik | Identity provider — SSO across all services |
| Guacamole | Remote desktop access via Cloudflare Tunnel |
| Joplin Server | Self-hosted notes sync |
| Uptime Kuma | Service uptime monitoring |
| Glances | System resource monitoring |
| Garage S3 + WebUI | S3-compatible object storage for Longhorn backups |
| Rsync endpoint | Off-site backup target from Synology NAS |
| OpenClaw | AI infrastructure agent (Telegram → kubectl/flux/docker) |
This entire app layer lives in its own repo, cloudlab-merox — one docker-compose.yml per service, the canonical source for everything in the table above. The infrastructure repo’s Ansible roles deploy it: app_stack_setup clones cloudlab-merox and brings the compose stack up, while cloudflared_setup deploys the Cloudflare Tunnel connector as a network_mode: host container, authenticated with a connector token in Ansible Vault (cloudflare_tunnel_token). Ingress rules live on Cloudflare’s side (config_src: cloudflare) — nothing to reconfigure per-deploy.
Tailscale Split DNS routes every *.cloud.merox.dev query to the Pi-hole above over the tailnet — devices on the mesh resolve straight to the VPS’s Tailscale IP, no Cloudflare round-trip for internal traffic, while anything outside the mesh still goes through the tunnel. That IP is pinned in vars.yml and checked on every DR rebuild — dr-verify fails loudly if the new VPS gets a different 100.x.x.x address, since Split DNS would otherwise silently break.
Authentik acts as the identity layer for everything — Google SSO, proxy authentication for Guacamole, OAuth2 for Portainer, and a Kubernetes outpost for cluster services. Full Authentik setup →
OpenClaw is a self-built AI agent that connects Telegram to the infrastructure — kubectl, flux, and docker commands via chat, from anywhere on the Tailscale mesh. Full OpenClaw setup →
Tip
The Oracle instance doubles as a Tailscale exit node — useful for routing traffic through the US when needed.
Disaster Recovery
Oracle can and does terminate Always Free instances without warning. I don’t depend on that not happening.
The full stack — Ansible roles + Terraform, plus the cloudlab-merox app layer — lives across two repos under vps/. make dr-full provisions an on-demand Hetzner VPS, deploys the Ansible roles, and brings up the full cloudlab-merox stack in one shot, ~15 minutes. Hetzner is not a standing server — it’s spun up only when Oracle is lost, then torn down after migration back. Cloudflare Tunnel reconnects automatically with the same vault-stored connector token, and Tailscale rejoins the mesh with the same auth key — vault also tracks that key’s expiry, so dr-preflight fails loudly if it’s gone stale.
make dr-preflight # checks vault, age.key, Tailscale key + expiry, toolsmake dr-full # terraform apply + ansible setup + app-stack deploy (~15 min)make dr-restore # pulls NAS backups, restores DBs + service state (non-interactive)./scripts/dr-verify.sh --phase 1 # post-DR verificationmake dr-full └─ terraform apply (~2 min) — new Hetzner server, inventory updated └─ ansible setup (~12 min) — infra roles + cloudlab-merox app stack deployed
make dr-restore └─ pull from NAS — rsyncd pull of /srv/backups + Garage bucket └─ restore DBs — Authentik + Joplin from latest dump └─ restore extras — Guacamole, Traefik certs, Pi-hole, Homepage, Portainer, OpenClawTwo commands, ~15-20 minutes total, and the box is back where it was — dr-verify also re-checks the VPS’s Tailscale IP against the pinned value, since Split DNS for *.cloud.merox.dev depends on it staying put.
For the full walkthrough including security hardening, Ansible vault setup, and the Terraform config: Oracle Cloud Free Tier: Building a Full DR Plan →
Backup
The guiding principle after the latest redesign: only back up state that can’t be rebuilt from Git. Everything declarative — K8s manifests, Ansible roles, Terraform, SOPS-encrypted secrets — lives in the infrastructure repo and needs no separate backup. What’s left is surprisingly small, and every piece of it has an off-site copy, in both directions:
Homelab Oracle Cloud VPS─────── ────────────────K8s media/ARR configs ── Longhorn ──▶ Garage S3 (02:00, retain 3)Synology NAS ──────── HyperBackup ──▶ /backup/synology (evening, ~25GB)
Oracle Cloud VPS Homelab──────────────── ───────DB dumps + service state ──────────▶ /srv/backups (01:15–01:30, 7-day retention)/srv/backups + Garage ◀── NAS pulls ─ Synology NAS (03:30, rsync)
Longhorn → Garage S3, opt-in only. Volumes are enrolled via a PVC label (recurring-job-group.longhorn.io/media: enabled) — just the Jellyfin and *arr stack configs, the stuff that takes hours to reconfigure by hand. Prometheus/Loki/Grafana history, Netdata, and all cache volumes are deliberately excluded: they’re regenerable noise that used to inflate the backup set to ~41GB; the trimmed set is a few GB. Garage replaced MinIO after MinIO discontinued their Docker images and left older builds with known CVEs. MinIO → Garage migration →
VPS state → nightly dumps. Authentik and Joplin get daily pg_dumps; Guacamole connections, Traefik’s acme.json, Pi-hole config, and the OpenClaw agent runtime (secrets excluded) get daily tars — all into /srv/backups/ with 7-day retention, deployed by the vps_backup Ansible role.
VPS → Synology NAS, the off-site for the off-site. Every night the NAS pulls /srv/backups/ plus the entire Garage bucket (data + metadata snapshots) over Tailscale. Fun implementation detail: Synology’s patched rsync refuses server-mode over SSH unless DSM’s “rsync service” is enabled, so instead of pushing, the VPS SSHes into the NAS and has it pull from read-only rsyncd modules. A dead VPS now costs at most one day of backups.
Synology NAS → rsync to the same Oracle VPS (~25GB of Docker volumes, configs, and data via HyperBackup) — the reciprocal direction, so NAS data survives a house-level failure. Synology backup setup →
Synology local redundancy — 2× 2TB in RAID1 for the primary NAS data.
For the full backup philosophy, retention policies, and restore procedures: 3-2-1 Backup Strategy →